ARTIKEL: WIE KI DIE IDENTIFIZIERUNG VON KONFIGURATIONSEINHEITEN REVOLUTIONIERT
Bei digitalsalt machen wir aus komplexen Prozessen überschaubare Aufgaben. Unser Team aus erfahrenen Experten und Beratern vereint Wissen aus verschiedenen Bereichen, darunter Softwareentwicklung, Datenanalyse und integrierte Logistikunterstützung. Wir schrecken nicht vor Herausforderungen zurück und machen uns stets auf die Suche nach innovativen Lösungen.
Eine dieser Herausforderungen war ein kürzlich durchgeführtes Projekt, bei dem es um die Identifizierung von Configuration Items (CIs) in einer großen Stückliste mit über 60.000 Positionen ging. Die Aufgabe war komplex, aber wir sahen darin eine Gelegenheit, die Leistungsfähigkeit von Künstlicher Intelligenz (KI) bei der Rationalisierung solcher Prozesse zu demonstrieren.

Mit Hilfe der KI-basierten Bildsynthese erstelltes Bild

Ungenaues und zeitaufwändiges manuelles Verfahren
Unser Kunde stand vor der Herausforderung, Configuration Items (CIs) in einer großen Bill of Materials (BoM) mit über 60.000 Positionen zu identifizieren. Die Aufgabe war sehr komplex und brachte ein hohes Risiko für Ungenauigkeiten und Ineffizienzen, hohe Zeit- und Ressourcenkosten und potenziell kritische Fehler mit sich.
Implementierung des Machine Learning Ansatzes
Um die Herausforderung zu bewältigen, entwickelten wir einen umfassenden Ansatz für den Lebenszyklus des maschinellen Lernens. Dazu gehörten Zielidentifizierung, Datenerfassung, -bereinigung, -verarbeitung, explorative Datenanalyse, Modelltraining, Testen, Parameterabstimmung, Feature Engineering, Modellbewertung, Optimierung und Einsatz.


Profitieren Sie von 98% Genauigkeit
Das Machine Learning Modell war in der Lage, CIs und Nicht-CIs in einem großen BoM mit einer beeindruckenden Genauigkeit von 98 % zu identifizieren. Dies sparte nicht nur Zeit und reduzierte Fehler, sondern lieferte auch wertvolle Erkenntnisse, die die Entscheidungsfindung unterstützen konnten.
Lesen Sie weiter, wenn Sie wissen möchten, wie der Vorgang im Detail aussieht.
Die Herausforderung: Konfigurationselemente und Stücklisten
Ein Configuration Item (CI) ist jede Hardware, Software oder Kombination aus beidem, die eine Endnutzungsfunktion erfüllt und für ein separates Konfigurationsmanagement vorgesehen ist. Bei der Identifizierung eines CI ist zu prüfen, ob es…
- im Falle eines Ausfalls die Sicherheit gefährden könnte,
- einen vollständigen Ausfall der Plattform/des Systems verursachen kann,
- eine speziell entwickelte Software oder Firmware enthält, die nicht als Teil eines Hardware Configuration Item (HWCI) verwaltet wird,
- Schnittstellen zu anderen Plattformen, Systemen oder Geräten aufweist,
- oder Leistungsspezifikationen und Testanforderungen enthält.
Im Gegensatz dazu ist eine Stückliste (Bill of Materials, BoM) eine umfassende Liste von Teilen, Artikeln, Baugruppen und anderen Materialien, die zur Herstellung eines Produkts benötigt werden.
Die Herausforderung liegt in der schieren Menge und Komplexität der Daten, die zu Ungenauigkeiten und Ineffizienzen führen können, die Zeit und Ressourcen kosten und potenziell zu kritischen Fehlern führen.
Die Auswirkungen: Reale Kosten der Ungenauigkeit und die Macht der KI
Die Kosten für Ungenauigkeiten bei der Identifizierung von Configuration Items (CI) können erheblich sein. Wird ein CI falsch identifiziert, kann dies zu einem Ausfall eines kritischen Systems führen, was Ausfallzeiten, Produktivitätsverluste und potenzielle Sicherheitsrisiken zur Folge hat. Darüber hinaus kann der Zeit- und Ressourcenaufwand für die manuelle Identifizierung von CIs und Nicht-CIs in einem großen BoM erheblich sein, wodurch wertvolle Ressourcen von anderen wichtigen Aufgaben abgezogen werden und die Wahrscheinlichkeit menschlicher Fehler steigt.
Laut einer Studie von McKinsey wird erwartet, dass KI die Leistung in allen Branchen steigern wird, insbesondere in solchen mit einem hohen Anteil an vorhersehbaren Aufgaben. KI-gestützte Arbeit könnte eine zusätzliche wirtschaftliche Produktion von etwa 2,6 Billionen bis 4,4 Billionen Dollar jährlich erzeugen. Eine durch KI verbesserte vorausschauende Wartung ermöglicht eine bessere Vorhersage und Vermeidung von Maschinenausfällen, wodurch die Produktivität von Anlagen um bis zu 20 % gesteigert und die gesamten Wartungskosten um bis zu 10 % gesenkt werden könnten. Je nach Komplexität der Aufgabe und Effizienz des KI-Modells kann der Zeitaufwand um 20 % bis 50 % oder sogar noch mehr reduziert werden.
Unser Ansatz: Der Machine Learning Lifecycle
Um die oben erwähnte Herausforderung der Identifizierung von CIs im BoM zu bewältigen, haben wir einen umfassenden Ansatz für den Lebenszyklus des maschinellen Lernens gewählt. Dieser umfasst:
Identifizierung des Ziels: Unser Hauptziel war die genaue Unterscheidung zwischen CIs und Nicht-CIs innerhalb des BoM. Dies erforderte ein tiefes Verständnis der spezifischen Merkmale von CI und ihrer Unterschiede zu Nicht-CI.
Datenerhebung, -bereinigung und -verarbeitung: Wir sammelten die erforderlichen Daten aus dem BoM, einschließlich Informationen wie Artikelbezeichnung, Menge, Gewicht usw. Diese Daten wurden in ein für den Algorithmus verdauliches Format umgewandelt und dienten als Grundlage für unser Machine-Learning-Modell.

Worteinbettungen sind dichte Vektordarstellungen, die semantische und kontextuelle Informationen erfassen. Durch die Darstellung von Wörtern in einem kontinuierlichen Vektorraum ermöglichen Worteinbettungen Algorithmen, die kontextuellen Ähnlichkeiten zwischen Wörtern zu berücksichtigen.
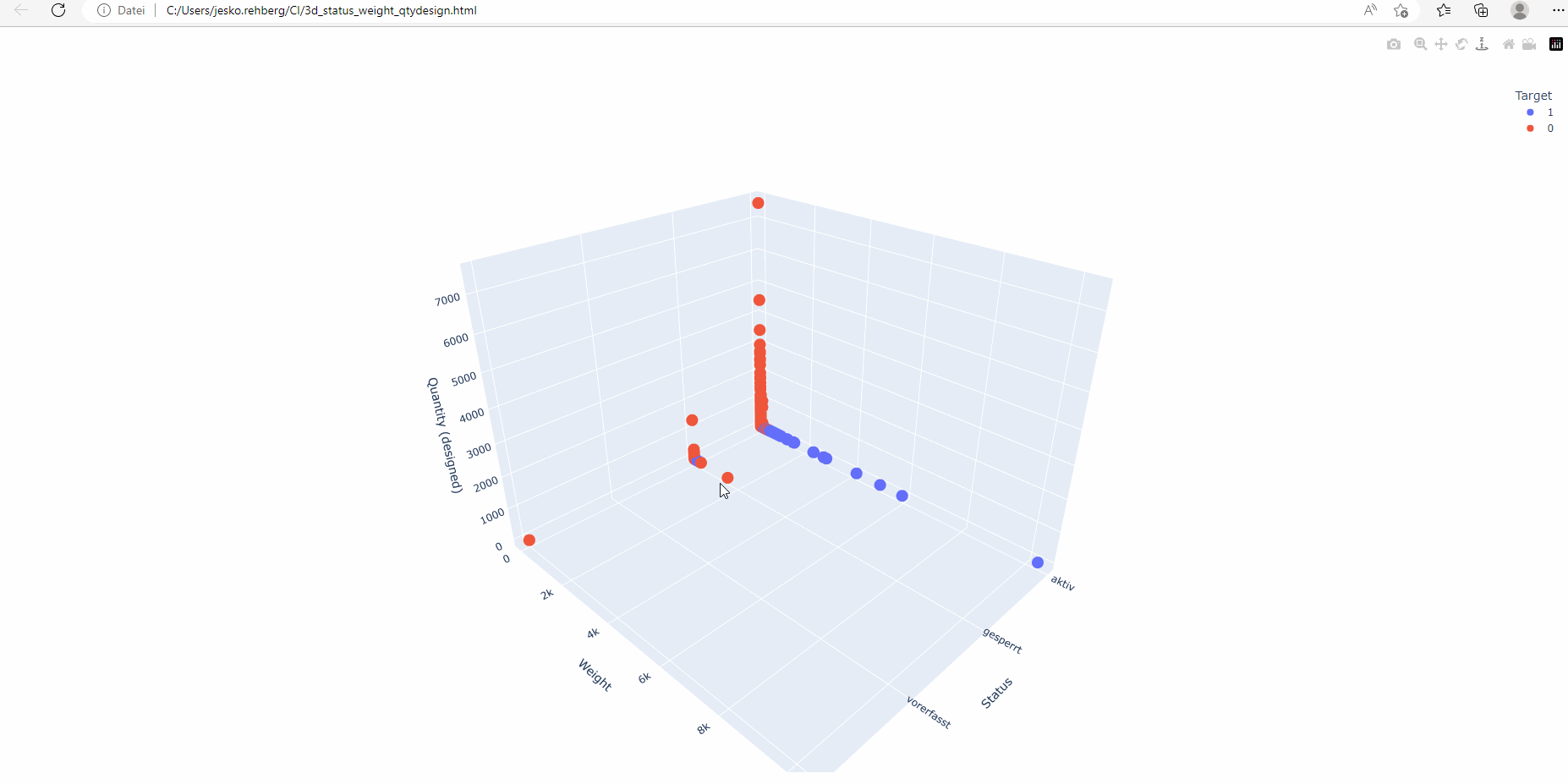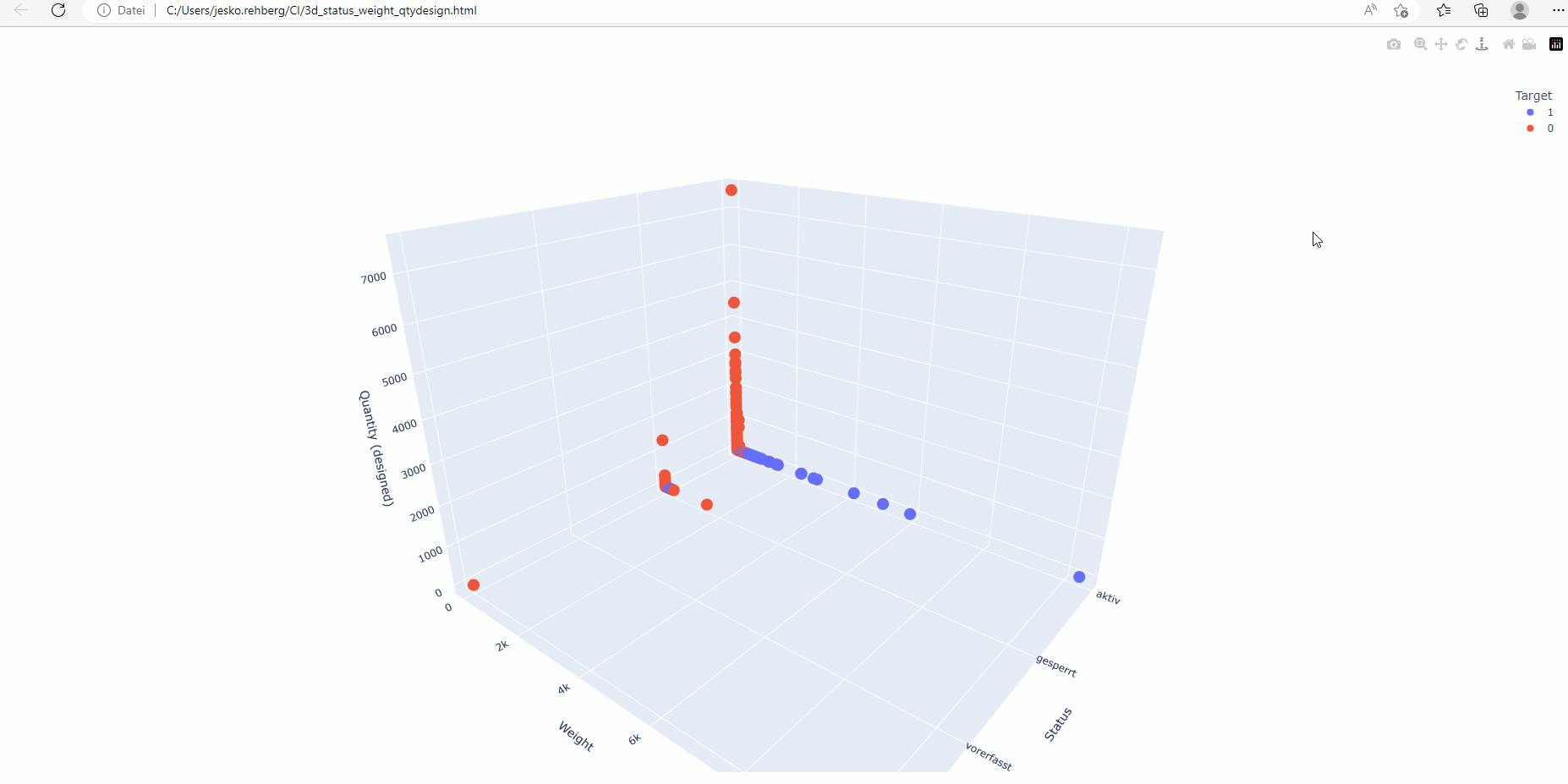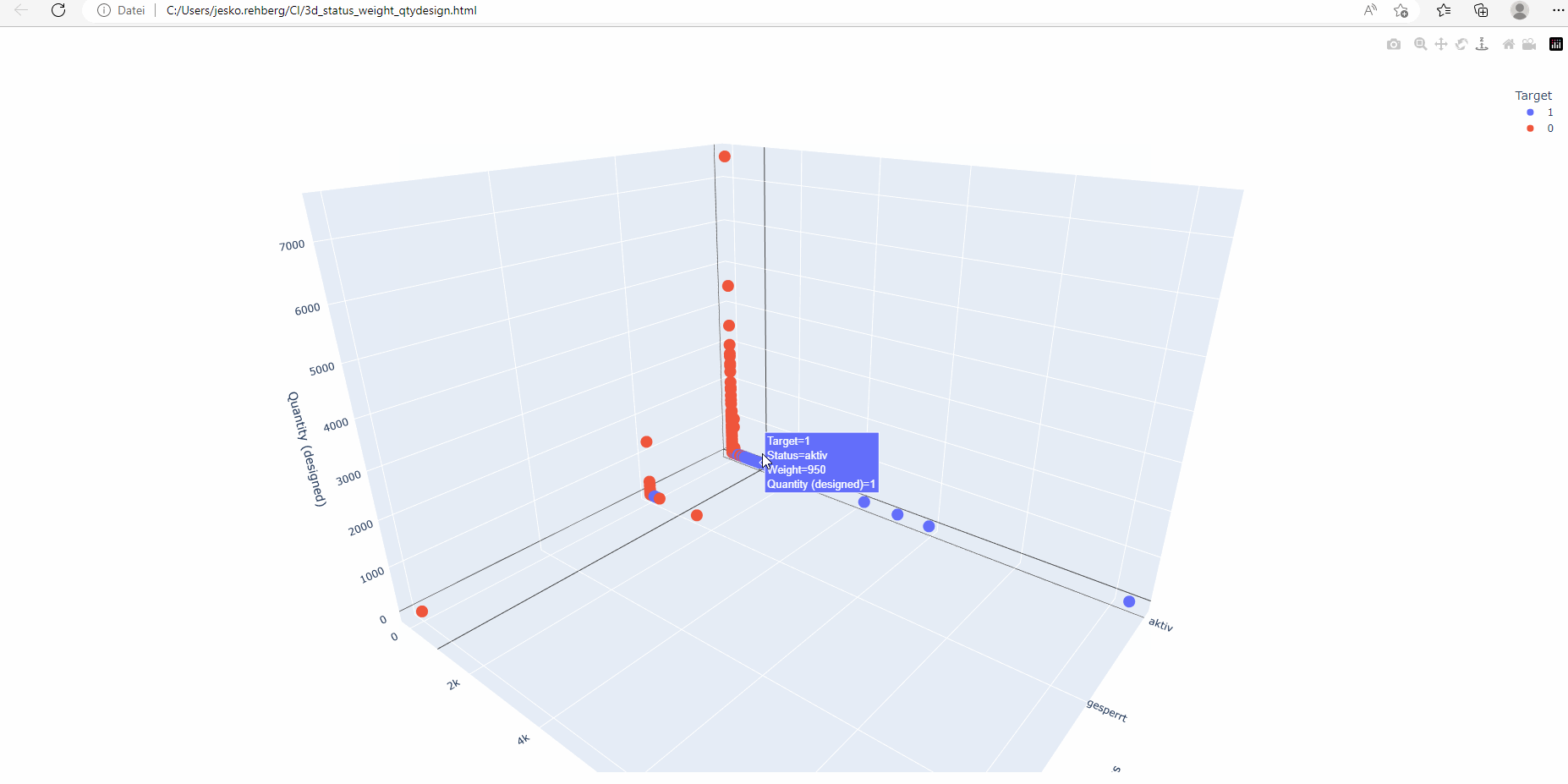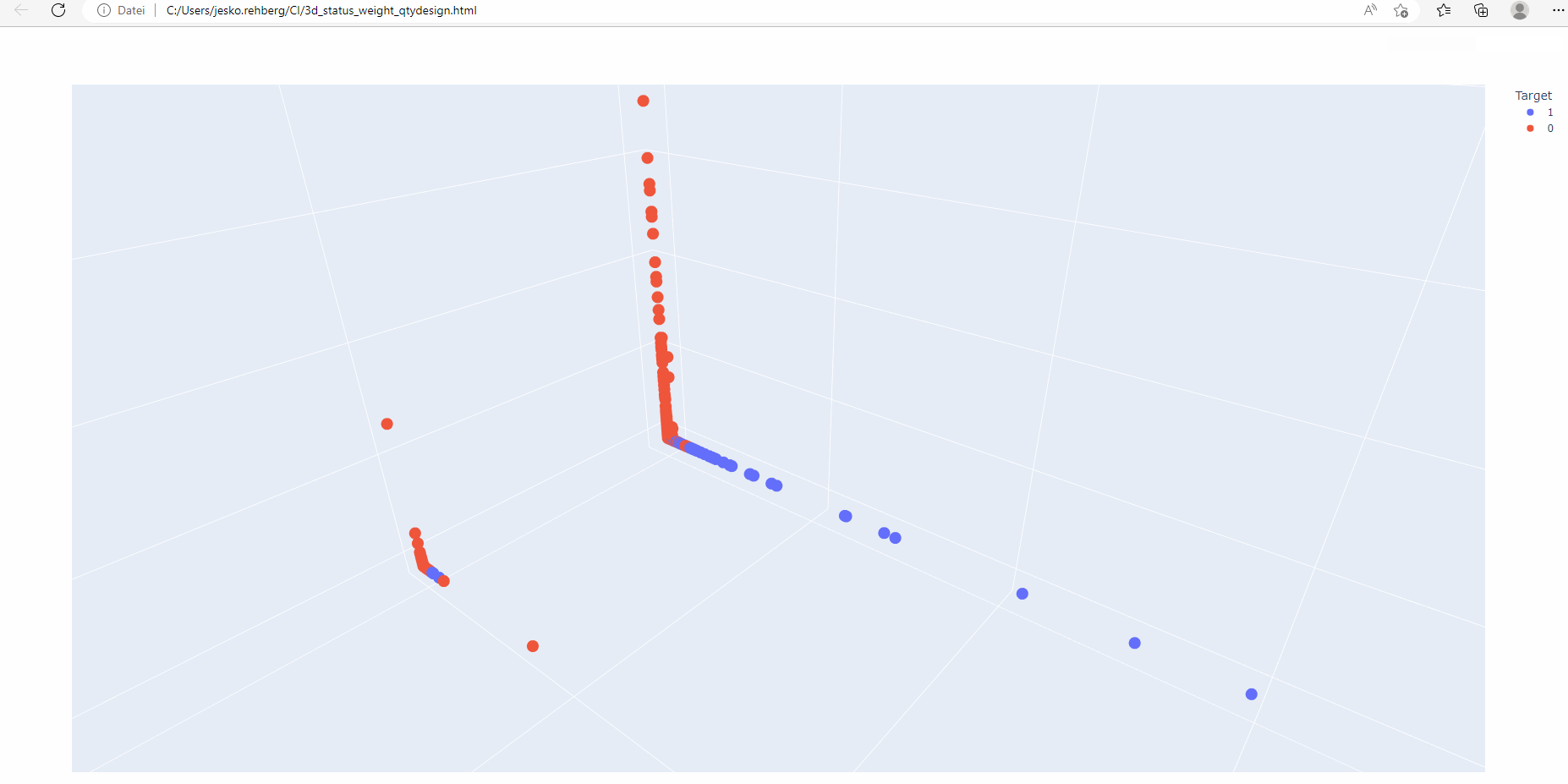
Mehrdimensionale Diagramme sind besonders nützlich, wenn es um mehrere Merkmale geht. Durch die Anzeige von Datenpunkten in einem 3D-Raum können Menschen visuelle Einblicke in die Interaktion verschiedener Variablen und deren Auswirkungen auf die CI-Klassifizierung gewinnen.
Explorative Datenanalyse (EDA): Bevor wir mit der Modellbildung begannen, führten wir eine eingehende EDA durch. Dieser Schritt umfasste die Visualisierung der Daten, die Identifizierung von Ausreißern, den Umgang mit fehlenden Daten und das Verständnis der zugrunde liegenden Muster und Beziehungen innerhalb der Daten. Dieser Prozess half uns, die Struktur unserer Daten besser zu verstehen, und diente als Leitfaden für unsere weiteren Schritte.
Modelltraining und -test: Wir nutzten die Technik der Worteinbettung, um Wörter in numerische Vektoren in einem hochdimensionalen Raum umzuwandeln. Mit dieser Methode konnten wir die semantischen und syntaktischen Beziehungen zwischen Wörtern erfassen, die bei der Identifizierung von CIs und Nicht-CIs eine entscheidende Rolle spielen. Wir trainierten unser Modell auf einem Teil unserer Daten und testeten es dann auf ungesehenen Daten, um seine Leistung zu bewerten.

Training des Modells: Beim Training wird das Modell mit Eingabedaten und entsprechenden Zieldaten gefüttert, um seine internen Parameter zu optimieren und genaue Vorhersagen zu treffen. Während jeder Epoche aktualisiert das Modell seine internen Parameter durch einen Prozess namens “Backpropagation”, bei dem es den Verlust zwischen seiner vorhergesagten Ausgabe und der tatsächlichen Zielausgabe berechnet und die Parameter anpasst, um diesen Verlust mithilfe eines Optimierers zu minimieren
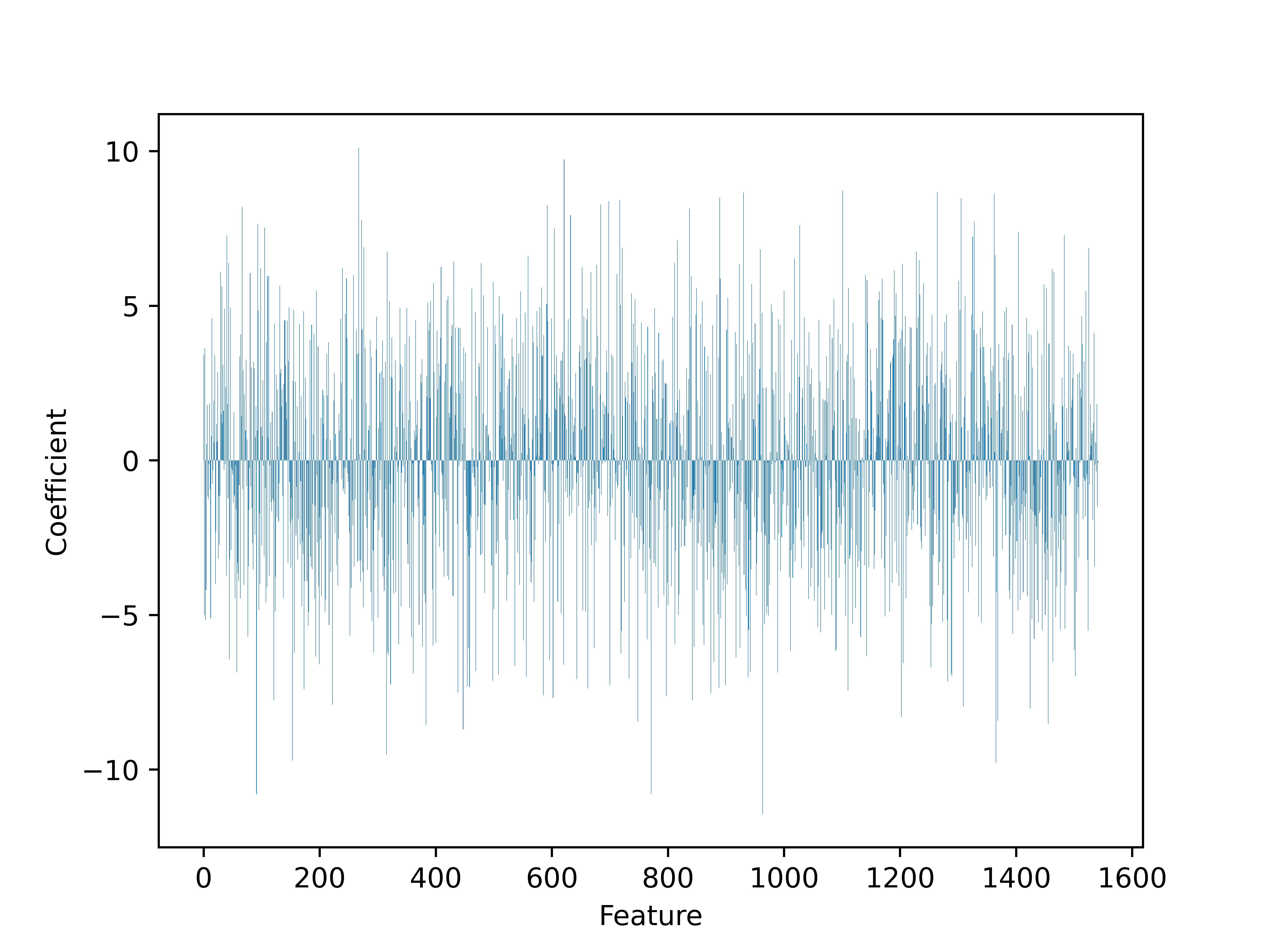
Merkmalsbedeutung: Jedem Eingangsmerkmal werden Merkmalskoeffizienten oder -gewichte zugewiesen, um die Bedeutung jedes Merkmals für den Entscheidungsprozess des Modells anzugeben.
Parameterabstimmung und Merkmalstechnik: Nach dem anfänglichen Trainieren und Testen des Modells nahmen wir eine Feinabstimmung der Modellparameter vor, um seine Leistung zu verbessern. Dazu wurden verschiedene Hyperparameter des Modells angepasst. Außerdem haben wir neue Merkmale aus den vorhandenen Daten entwickelt, um unserem Modell informativere Eingaben zu liefern. In der folgenden Grafik sind die Merkmale auf der x-Achse und die entsprechenden Koeffizienten auf der y-Achse dargestellt. Die wichtigsten Merkmale sind diejenigen, die die höchsten absoluten Koeffizientenwerte aufweisen, da sie den größten Einfluss auf die Vorhersagen des Modells haben. Um festzustellen, welche Merkmale im Diagramm am wichtigsten sind, suchen Sie nach den höchsten Balken (entweder positiv oder negativ). Diese stellen die Merkmale mit den höchsten absoluten Koeffizientenwerten dar und haben daher den größten Einfluss auf die Vorhersagen des Modells.
Modellbewertung und -optimierung: Wir bewerteten die Leistung unseres Modells anhand geeigneter Metriken. In unserem Fall war die Genauigkeit eine Schlüsselkennzahl, da unser Ziel darin bestand, CIs und Nicht-CIs korrekt zu identifizieren. Auf der Grundlage der Bewertung haben wir unser Modell weiter optimiert, um die bestmögliche Leistung zu erzielen, wobei wir sowohl auf Unteranpassung als auch auf Überanpassung geachtet haben: Es ist wichtig, die potenziellen Fallstricke im Zusammenhang mit dem Fluch der Dimensionalität zu erkennen.
Einsatz des Modells: Sobald wir mit der Leistung unseres Modells zufrieden waren, setzten wir es für den Einsatz ein. Dies bedeutete, dass das Modell in den bestehenden Arbeitsablauf integriert werden musste, damit es durch die genaue Identifizierung von CIs und Nicht-CIs im BoM einen Mehrwert bieten konnte. Das Modell kann sowohl als lokale, eigenständige Anwendung als auch in der Cloud bereitgestellt werden.
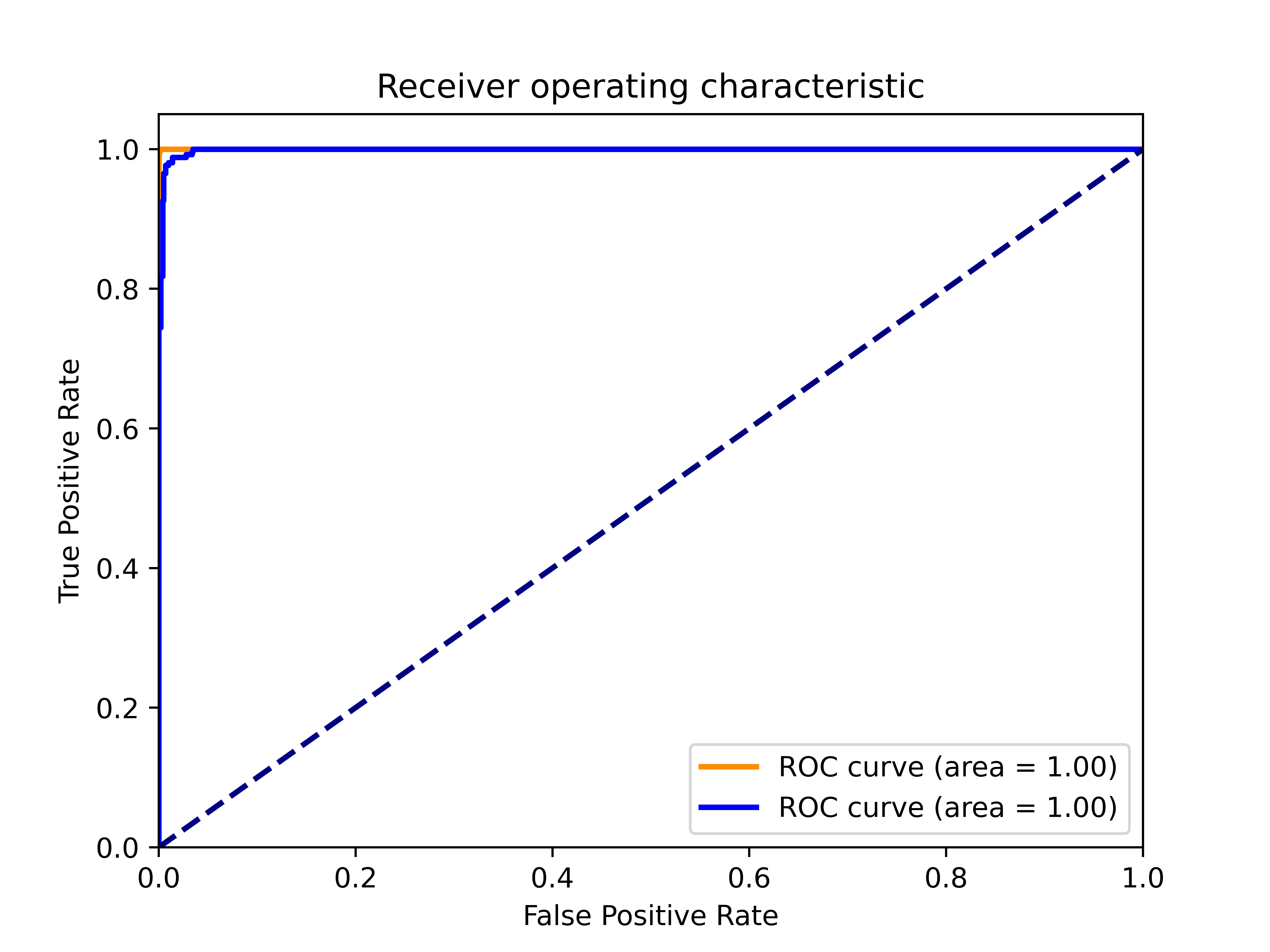
Bewertung der Leistung mit der ROC-Kurve (Receiver Operating Characteristic) Die ROC-Kurve wird zur Bewertung der Leistung des CI-Klassifizierungsmodells verwendet. Sie stellt das Verhältnis zwischen der Rate der echten positiven Fälle (TPR) und der Rate der falschen positiven Fälle (FPR) bei verschiedenen Klassifizierungsschwellenwerten dar. Die Wahr-Positiv-Rate, auch als Sensitivität oder Recall bezeichnet, stellt den Anteil der tatsächlich positiven Instanzen dar, die vom Modell korrekt als positiv klassifiziert wurden. Die Falsch-Positiv-Rate hingegen misst den Anteil der tatsächlich negativen Instanzen, die vom Modell fälschlicherweise als positiv eingestuft werden.
Das Ergebnis: Nutzung von KI für eine präzise CI-Identifizierung
Unser Modell für maschinelles Lernen war in der Lage, CIs und Nicht-CIs in einem großen BoM mit einer beeindruckenden Genauigkeit von 98 % zu identifizieren. Dies spart nicht nur Zeit und reduziert Fehler, sondern liefert auch wertvolle Erkenntnisse, die zur Entscheidungsfindung beitragen können.
Im Sinne einer kontinuierlichen Prozessoptimierung unterziehen wir das Modell einer ständigen Bewertung. Der “menschliche Experte” wird das Modell jederzeit überprüfen können. Stellt sich im Laufe der Zeit heraus, dass die Vorhersagegenauigkeit des Modells aufgrund veränderter Rahmenbedingungen abnimmt, wird dies durch eine automatische Überwachung erkannt. Im Zusammenspiel von Domänen- und KI-Expertise werden innerhalb des Zyklus die entsprechenden Stellschrauben justiert, bis die Vorhersagequalität des Modells wieder innerhalb der gewünschten Spezifikation liegt.
Unseren Entscheidungsbäumen ist bei dieser CI-Klassifizierungsaufgabe metaphorisch gesprochen ein weiterer (Projekt-)Zweig gewachsen: Wir können CI-Dokumente in natürlicher Sprache durchsuchen und beantworten lassen. Dies geht über eine reine Stichwortsuche hinaus, da unser Modell den Kontext der Frage erfasst und auch die Antwort aus verschiedenen Dokumenten zusammenfassen kann. Die Einbeziehung menschlicher Feedbackschleifen in dieses Frage-Antwort-System ist das Besondere an unserem Ansatz.
Die Lücke schließen: Wir denken immer über den Tellerrand hinaus und versuchen, ganzheitliche und nachhaltige Lösungen für unsere Kunden anzubieten. Durch die Integration von Programmierung, Statistik, Business Intelligence und KI maximieren wir den Datennutzen für unsere Kunden.
Unser jüngstes Projekt ist ein Beweis für unseren innovativen Ansatz und unsere Fähigkeit, unseren Kunden einen Mehrwert zu bieten. Wir sind begeistert vom Potenzial der KI und des maschinellen Lernens zur Lösung komplexer Herausforderungen und freuen uns darauf, unseren Kunden auch weiterhin innovative, wertschöpfende Lösungen zu bieten.
IHR KONTAKT
Sie möchten mehr wissen oder benötigen unseren Support?
Wir freuen uns darauf von Ihnen zu hören!
